
sihyeon.train()
VAE(Variational Autoencoder) & ELBO 이해하기 본문
1. Autoencoder의 문제점
일반적인 Autoencoder는 입력 데이터를 압축시킨 후 복원하는 데에 초점을 맞추는 모델입니다.
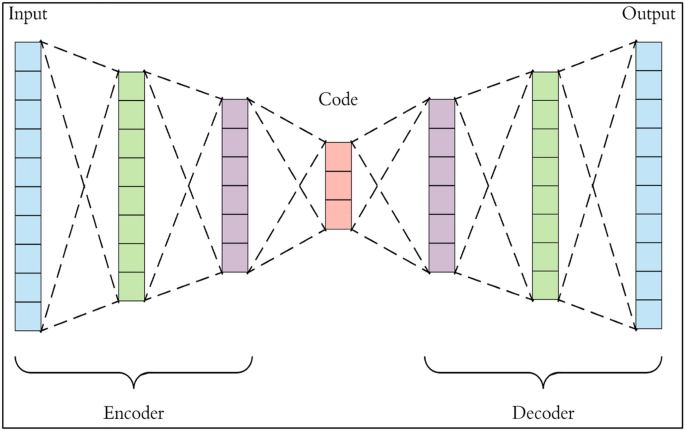
Autoencoder:
- Encoder는 입력 데이터 X 를 저차원의 잠재 벡터 Z 로 압축(차원 축소)
- Decoder는 잠재 벡터 Z 를 입력으로 받아 X 를 복원(X̂)
- 복원한 X̂ 와 X 사이의 재구성 오차(reconstruction loss, MSE or BCE)를 최소화함이 목적
Autoencoder는 오직 학습 데이터를 압축했다가 복원하는 재구성 오차만을 기준으로 학습되기 때문에 잠재 공간 상에서의 구조를 직접적으로 제어하지 않습니다. 따라서 학습된 z가 몰려 있는 영역을 벗어난 임의의 지점은 decoder에 의해 해석될 수 없는 무의미한 잠재 벡터를 가질 수 있습니다.
생성 모델로 활용하기 위해서는 잠재 공간의 한 지점에서 다른 지점으로 조금씩 움직일 때 decoder의 출력도 그에 따라 자연스럽게 변화해야 합니다. 예를 들어, 잠재 공간에서 샘플링을 할 때 웃는 얼굴의 잠재 벡터 zsmile에서 우는 얼굴의 잠재 벡터 zcry로 가는 경로를 따라가면 decoder는 그 중간의 표정들을 연속적으로 생성할 수 있어야 합니다. 그러나 AE는 학습한 point가 아닌 지점에서 완전히 해석할 수 없는 이미지를 출력할 수 있습니다. 이러한 문제를 해결하기 위해 등장한 것이 VAE(Variational Autoencoder)입니다.
2. VAE
VAE는 확률적 잠재 공간(probabilistic latent space)라는 개념을 도입하여 데이터들의 의미 있는 잠재 분포를 학습하는 것을 목표로 합니다.
하나의 image 데이터 x 는, 어떠한 잠재 요인 z (다차원 실수 벡터)가 있어서 만들어진 것이라는 가정을 합니다.
- x: 고양이 사진
- z: 고양이 품종, 자세, 배경, 조명, 표정, ...
대개 z 는 눈에 보이지 않는 속성들이며 VAE는 해당 요인 z 의 연속적인 확률 공간을 모델링하는 것을 목적으로 합니다.
잠재 요인 z 로부터 x가 생성되므로 x ~ p(x|z)입니다. 그러나 z는 우리가 알지 못하는 정보입니다. 모델은 X 를 통해서 Z 를 먼저 추론해야 합니다. 즉, p(z|x) ㅡ 사후 분포를 추론합니다.
AE가 데이터를 완벽히 복원하는 데에만 집중하여 고정 잠재 벡터 z를 만드는 방식에 초점을 맞춘다면, VAE는 잠재 벡터 z 자체를 확률 변수로 모델링하며 입력 x에 대해 평균과 분산을 출력함으로써 z ∼ N(μ,σ2)의 형태로 분포를 정의합니다.
1) 구조도

- AE의 encoder가 고정된 잠재 벡터 z를 출력하는 반면, VAE의 encoder은 qϕ(z|x) 확률 분포의 평균과 분산을 출력합니다. 입력 데이터 x 가 어떠한 z 로부터 생성되었을지를 나타내는 사후 분포입니다.
- 사후 분포에서 벡터 z 를 샘플링합니다. 이때 샘플링 연산은 stochastic이기 때문에 직접 z 를 샘플링하게 되면 역전파가 불가하므로 N(0, I)분포에서 표준 정규 노이즈를 샘플링하여 z = μ + σ ⋅ε 으로 z를 정의합니다. 이것이 reparameterization trick입니다. ε는 독립적인 벡터값이므로 역전파 연산에 영향을 주지 않습니다.
- decoder에서 pθ(x|z)에 따라 z 로부터 x̂ 를 복원합니다.
encoder에서 실제 사후 분포 p(z|x)와는 다른 q(z|x)를 출력하고 있습니다. 이제 q(z|x)가 무엇이며 왜 필요한지 살펴보고, VAE는 어떠한 Loss를 사용하는지 알아볼 것입니다.
2) 변분 추론(Variational Inference)

- 베이즈 정리에 따라, 사후 분포는 위와 같이 정의할 수 있습니다.

- 조건부 확률의 정의입니다.
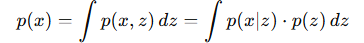
- z 가 연속형 실수 벡터이므로 적분하여 오로지 x 의 확률을 얻을 수 있습니다: marginalization
그러나 z 는 수십~수백 차원의 고차원 벡터입니다. 고차원 공간에 대한 복잡한 함수의 적분을 계산하는 것은 사실상 불가능합니다. 또, p(x|z)는 비선형 모델인 decoder를 통해 모델링되므로 x와 z 사이의 관계가 매우 복잡합니다. 이런 비선형 함수의 적분은 거의 항상 다루기 어렵습니다. 마지막으로 p(x)는 관측 데이터 x의 실제 분포를 나타냅니다. 이미지나 텍스트와 같은 실제 데이터의 분포는 매우 복잡하며 이를 수학적으로 직접 정의하거나 계산하는 것 역시도 불가능합니다.
결국 p(x)를 정확히 계산할 수 없기 때문에 VAE는 직접 p(z|x)를 계산하는 대신, q(z|x)라는 간단한 분포를 통해 이를 근사하고, 근사를 이용해 로그 우도 log p(x)의 Evidence Lower Bound (ELBO)를 최대화하는 방식으로 학습을 진행합니다.
3) ELBO
- 로그 우도를 최대화해야 하지만 다음의 형태는 적분 계산이 불가능합니다.
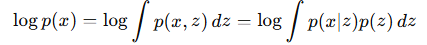
- 간단한 분포 q(z|x)를 도입합니다. 이때 q(z|x)f(z)를 z에 대해 적분하는 것은, q(z|x)라는 확률 분포를 따르는 f(z)의 기댓값을 의미합니다.
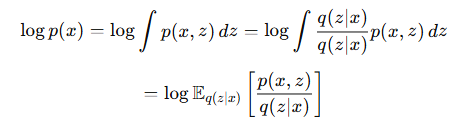
- 젠센 부등식: 함수 f가 오목 함수(ex. log)라면 다음이 성립합니다.
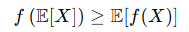
- 젠센 부등식에 의해 로그 우도의 하한을 다음처럼 정의할 수 있습니다.
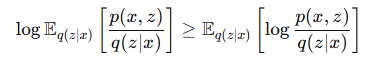
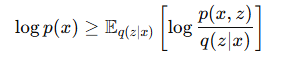
- 우변을 전개합니다.
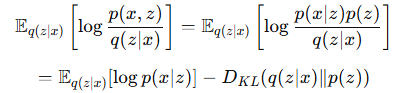
이것이 ELBO입니다. reconstruction term과 regularization term으로 이루어져 있습니다.
reconstruction term은 decoder가 잠재 벡터 z로부터 x를 잘 복원하는지를 측정하며, regularization term은 encoder가 출력한 사전 분포 q(z|x)가 정규 분포와 얼마나 다른지를 측정합니다. 이 항을 작게 만들면 사후 분포들이 정규화되며 잠재 공간 내 모든 분포들이 N(0, I)에 가까워지므로 어느 지점을 샘플링하여도 유의미한 생성이 가능하도록 합니다.
- ELBO는 로그 우도의 하한입니다. ELBO를 활용해 로그 우도를 정확히 표현하면 다음과 같습니다. 다음은 KL divergence의 정의입니다.

- 여기서 p(z|x) = p(x,z)/p(x)이므로
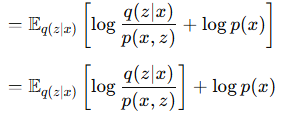
- 입니다. 이제 log p(x)를 좌변에 놓으면
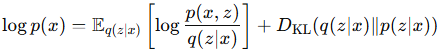
여기서 첫 번째 항은 ELBO였습니다. 그러나 KL divergence항의 p(z|x)를 계산할 수 없으므로(앞서 증명함) intractable하기에 학습에 활용할 수 없습니다. 때문에 우리는 ELBO 최대화를 로그 우도 최대화로 간주하고 학습합니다.

ELBO를 최대화해야 하므로 VAE에서 Loss는 음의 ELBO입니다.
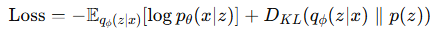
따라서 VAE는 확률적 encoder-decoder 구조를 통해 입력 데이터를 생성한 잠재 요인들의 분포를 모델링하며 그 분포를 통해 새로운 데이터를 생성할 수 있도록 학습됩니다.
'딥러닝 > 이론' 카테고리의 다른 글
| Self-Attention이란 + Colab 구조 구현 예제 (0) | 2025.06.23 |
|---|
